Extraire les images d'un pdf en gardant la transparence 11
Forums > Créativité

Pendant le confinement on est nombreux à vouloir tester le JdR par internet. On se dit alors que l'on va extraire/copier quelques images du pdf de son JdR favori pour illustrer roll20 ou équivalent. Dans acrobat reader on teste simplement de faire clique droit / copier sur l'image que l'on souhaite et on la colle dans notre logiciel de dessin préféré. Là c'est le drame, l'image est bien là mais elle est accompagnée d'un fond noir pas très joli. Il existe de multiples façons d'extraire des images d'un pdf tout en gardant la transparence du fond.
NitroPDF
La plus simple que j'ai pu tester m'a été donné par Murt. Il faut utiliser le logiciel NitroPDF (récupérable par exemple chez clubic)
La manipulation est très simple, on ouvre le pdf avec NitroPDF, on clique sur "Extract Images".
.jpg)
Cela ouvre un boite de dialogue :
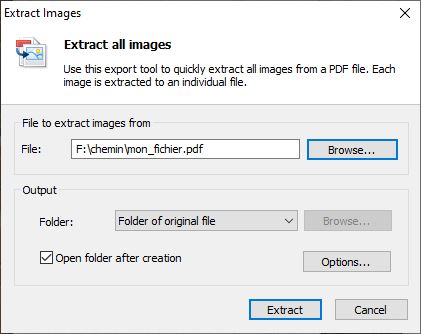
Vous pouvez choisir le dossier de destination pour les images. Par défaut elle iront dans le même dossier que le pdf.
Cliquer sur Extract et NitroPDF va se mettre à travailler 
FoxitReader
Comme acrobat reader, FoxitReader permet de copier une image dans un pdf avec un clic droit > Copier. Il suffit de coller l'image dans un logiciel de dessin pour la récupérer et l'enregistrer. Avec FoxitReader le fond de l'image est blanc, alors qu'avec acrobat il est noir. On répètera l'opération pour chaque image à extraire.
Si vous avez d'autres solutions n'hésitez pas à partager 
- Renfield

Je ne connais pas de méthodes aussi simples sous mac, je n'ai pas de mac. La méthode avec pdfimages devrait marcher si tu utilises les outils linux https://www.cyberciti.biz/faq/easily-extract-images-from-pdf-file/ Le soucis c'est que ça génère un fichier pour l'image et un fichier pour le masque / la transparence.
Il faut fusionner l'image avec son masque pour avoir de la transparence. On peut le faire avec ImageMagick comme je le décris dans ce message forums.php?topic_id=12676&tid=374894#msg374894

En sélectionnant une image puis clic droit, copier ? C'est un entre deux, on a pas la transparence (il y a un réglage ?) mais on a un fond blanc. Ce qui est le but recherché finalement dans la majorité des cas. Je le note comme possiblité dans le premier message.
- Renfield

Sur Mac j'ouvre les PDFs avec Gimp (la page avec la map ou l'image à récupérer) et j'ajoute la transparence sur la couleur de fond.

pdfimage, un outil en ligne de commande sous Mac et Linux.
Usage : pdfimage -all -f x -l y livre.pdf prefix
Remplacer x et y par le numéro de première et de dernière page sur lesquelles on veut récupérer une image. Les images des pages sélectionnées sont extraites et ont comme nom le prefix choisi suivi d'un nombre qui s'incrémente tout seul.
Ça extrait l'image telle qu'elle est dans le pdf. Donc après éditable avec son Gimp-like favori.
Si vraiment j'ai besoin d'un fond transparent, je passe un petit coup de GIMP pour rajouter la transparence. Sur un fond blanc ça se fait très facilement.
- Nioux
- et
- YulFi

Bien sûr mais dans ce cas on retombe sur le cas acrobat reader, fond noir ou blanc c'est pareil ça s'enlève facilement à coup de baguette magique. Le but là c'est d'avoir un outil simple et pour extraire rapidement une image parfaite. S'il faut jouer de la baguette magique c'est hors catégorie. C'est le plus lent et sur certaines illustrations ça ne se fait pas en un clic. Le top pour l'instant ça reste Nitro ça extrait toutes les images du pdf avec transparence. Simple et très rapide, la baguette magique à la poubelle 
@J2N Sous windows c'est aussi ce que j'utilisais jusqu'à hier cumulé à ImageMagick pour fusionner image et masque de transparence. Ca marche nickel.
